
The file robots.txt contains instructions for search engines regarding how they should crawl your website. These instructions, known as directives in English, are used to guide bots and specify certain search engines (or all) to refrain from scanning specific addresses, files, or parts of your site, whether it’s a WordPress site or any other type of site.
In this post, we’ll take an in-depth look at this file, particularly in the context of WordPress sites. I believe that by reading this post in its entirety, you’ll discover several things you might not have known about this unique file.
Before diving into detailed explanations about this special file, many who come to this post are interested solely in understanding how to guide search engines to avoid scanning a specific site and all its addresses. This is the relevant code for you in this case:
User-agent: *
Disallow: /What is the robots.txt file?
In general, bots and crawlers are a successful and perhaps even necessary concept for the Internet. However, this doesn’t mean that you, or any website owner, want these bots and crawlers to do as they please and scan every address and content indiscriminately.
The desire to control the behavior of bots, and the way they interact with sites on the web, led to the creation of a standard known as the Robots Exclusion Protocol.
The robots.txt file is, in fact, the practical implementation of the Robots Exclusion Protocol, allowing you to guide search engine bots on how to crawl your site.
For most website owners, the benefits of the robots.txt file can be summed up and divided into two categories:
- Optimizing the crawl budget and the resources that search engines allocate to your site. This is achieved by guiding and requesting to avoid wasting resources on scanning pages that you don’t want in the index. This action ensures that search engines will focus on scanning the most important pages on your site.
- Optimizing server performance and preventing overload due to scanning. This is done by blocking bots that consume unnecessary resources from scanning irrelevant addresses and content.
robots.txt is not intended for specific control over indexed pages
Using robots.txt, you can prevent search engines from accessing specific parts of your site, prevent the scanning of duplicate content and irrelevant content, and provide information to search engines on how to more efficiently scan your site.
The file indicates to search engines which pages and files they can scan on your site. However, it’s not a foolproof way to control which pages will appear in Google’s index and which won’t.
The approach to prevent a specific page from appearing in search results is to use the noindex tag – either at the code level on the specific page or at the server level (for instance, in the .htaccess file).
Although many website administrators have heard of the term robots.txt, it doesn’t necessarily mean they understand how to use it correctly. Unfortunately, I’ve seen numerous misguided instructions on this topic.
What does a robots.txt file look like?
For a WordPress site, for example, the robots.txt file might look something like this:
User-agent: *
Disallow: /wp-admin/Let’s explain the anatomy of the robots.txt file in the context of this example:
- User-agent – Indicates which user-agent (search engine) the following directives are relevant to.
- Asterisk (*) – Indicates that the directive is relevant for all user-agents, not specific ones.
- Disallow – This directive signifies which content should not be accessible for the specified user-agent.
- /wp-admin/ – This is the path that should not be accessible to the user-agent you’ve specified.
In summary, the example above instructs all search engine user-agents not to access the /wp-admin/ directory. Let’s delve into the various components of robots.txt…
1. User-agent in the robots.txt file
Each search engine must identify with a specific user-agent. For instance, Google’s bot is identified as Googlebot, Yahoo’s as Slurp, and Bing’s as BingBot.
The line that starts with “user-agent” signifies the beginning of a set of directives. All directives between the first user-agent mentioned and the subsequent one apply to that first user-agent.
2. Disallow directive in the robots.txt file
You can instruct search engines not to access specific files or pages, or even entire sections of your site, using the Disallow directive.
The Disallow directive should be followed by a path indicating which content should not be accessible to the specified user-agent. If no path is defined, search engines will disregard this directive.
User-agent: *
Disallow: /wp-admin/3. Allow directive in the robots.txt file
The Allow directive is used to counteract specific Disallow directives. Using both directives together allows search engines access to a specific file or page that would otherwise be inaccessible due to the Disallow directive.
The Allow directive also should be followed by a path indicating which content can be accessed. If no path is defined, the Allow directive is not relevant, and search engines will ignore it.
User-agent: *
Allow: /media/terms-and-conditions.pdf
Disallow: /media/In this example, the directive instructs all search engine user-agents not to access the /media/ directory, except for the PDF file mentioned in the Allow directive.
Important: When using these directives together, it’s advisable not to use wildcards, as this can lead to conflicting instructions.
Example of conflicting directives
User-agent: *
Allow: /directory
Disallow: *.htmlIn this scenario, search engines will likely be confused about the address http://domain.co.il/file.html, for example. It won’t be clear whether they should scan this file or not.
When certain directives are unclear to search engines, or at least less strict than others, Google will interpret the less strict directive, and in this case, it will scan the mentioned file.
4. Separate line for each directive
Each directive should appear on a separate line. Otherwise, search engines might misunderstand the instructions in the robots.txt file. Therefore, refrain from writing in this style:
User-agent: * Disallow: /directory-1/ Disallow: /directory-2/ Disallow: /directory-3/5. Using wildcards*
In addition to using wildcards for user-agents, you can also use them for URL addresses. For example:
User-agent: *
Disallow: *?In this example, there’s a directive instructing search engines not to access any URL address containing a question mark (?).
6. Using URL suffix ($) in the robots.txt file
You can use the dollar sign ($) to indicate a URL address suffix after the path. For example:
User-agent: *
Disallow: *.php$In this example, the directive prevents search engines from accessing and scanning any URL with the .php suffix.
However, addresses with parameters following that will still be accessible. For instance, the address http://example.co.il/page.php?lang=he will still be accessible, as it doesn’t end with .php.
7. Indicating the sitemap using robots.txt
Although the robots.txt file is intended to guide search engines on which pages they shouldn’t access, it’s also used to indicate where the XML Sitemap of the site is located.
Despite probably already adding the same site map using Google Search Console or Bing Webmaster Tools, it is recommended to provide a reference to this file in the robots.txt file as well. Multiple different Sitemap files can be referenced. Here’s an example:
User-agent: *
Disallow: /wp-admin/
Sitemap: http://example.co.il/sitemap1.xml
Sitemap: http://example.co.il/sitemap2.xmlThe guidance for search engines in this example is to not access the /wp-admin/ directory, and in addition, it indicates the presence of two Sitemap files located at the specified addresses.
The reference to the Sitemap file’s address should be absolute. Additionally, note that the address doesn’t necessarily need to be on the same server as the robots.txt file.
8. Adding Comments in the robots.txt File
Comments can be added using the hash symbol (#). These comments can appear at the beginning of a line or after the directive on the same line it applies to. Search engines will ignore anything following the hash symbol, and these comments are intended for humans only. Here’s an example:
# Don't allow access to the /wp-admin/ directory for all robots.
User-agent: *
Disallow: /wp-admin/And here’s an example where the comment is on the same line as the directive:
User-agent: * # Applies to all robots
Disallow: /wp-admin/ # Don't allow access to the /wp-admin/ directory.9. Using the Crawl-delay Directive in the robots.txt File
The Crawl-delay directive is not an official directive and exists to prevent overloading the server during crawling due to a high frequency of requests. If you encounter this situation, using Crawl-delay could be a temporary solution.
This situation likely indicates that the server hosting your site is weak and not suitable for your site’s needs. Alternatively, it’s possible that your site is not properly configured, and you should find a solution for that as soon as possible.
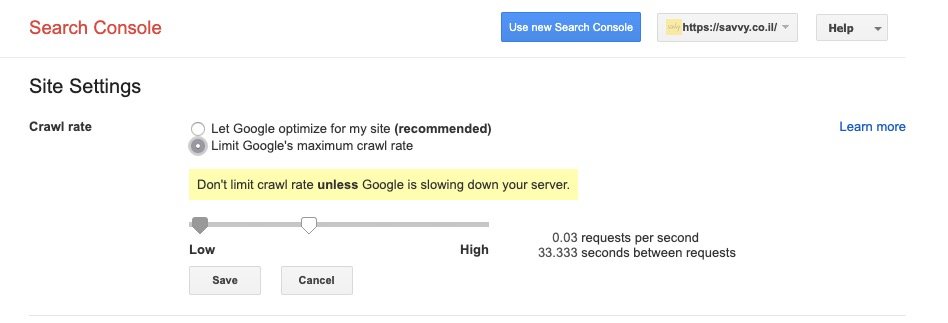
Different search engines interpret this directive differently, and Google’s bot doesn’t pay attention to this directive at all. However, Google does allow you to set the desired crawl rate through Google Search Console.
To set this in Search Console, log in to the old version of Search Console, select the property for which you want to adjust the crawl frequency, and make the necessary changes. By default, Google lets its bot decide on the most appropriate crawl frequency for your site.
 On the other hand, search engines like Yahoo and Bing do consider this directive but interpret it differently from each other. Check their documentation for more details. In any case, this directive could look like this:
On the other hand, search engines like Yahoo and Bing do consider this directive but interpret it differently from each other. Check their documentation for more details. In any case, this directive could look like this:
User-agent: BingBot
Disallow: /private/
Crawl-delay: 10How to Create and Edit the robots.txt File for WordPress Sites
WordPress automatically generates a virtual robots.txt file for your site, so even if you don’t take any action, a default file probably exists. You can check if this is the case by adding /robots.txt after your domain name.
For example, https://savvy.co.il/robots.txt will display Savvy Blog’s robots.txt file. If the file is indeed virtual and doesn’t exist physically on the server, you won’t be able to edit it.
If you want to make changes to the file, you need to create a physical file on your server. You can do this in several ways…
1. Creating a robots.txt File Using FTP
You can create and edit a robots.txt file using an FTP software. As a start, use a text editor to create an empty file named robots.txt.
Then, connect to your server via FTP and upload this file to the root folder of your site. Now you can make further modifications to the file using your FTP software.
2. Creating and Editing the robots.txt File Using Yoast SEO
If you’re using the Yoast SEO plugin for WordPress, you can create (and later edit) the robots.txt file directly through the plugin’s interface. To do this, go to the WordPress admin interface, then to SEO > Tools, and click on Edit Files.
If the robots.txt file doesn’t exist, you’ll have the option to create one. If it already exists, you’ll see the option to edit the file along with the option to edit the .htaccess file, which we will cover in a separate article.
Typical robots.txt File for WordPress Sites
The following code is intended specifically for WordPress sites. Keep in mind that this is a recommendation only and is relevant only if:
- You don’t want the WordPress admin interface (admin) to be crawled.
- You don’t want internal search result pages to be crawled.
- You don’t want tag pages and author pages to be crawled.
- You’re using pretty permalinks as recommended…
User-agent: *
Disallow: /wp-content/plugins/ # block access to the plugins folder
Disallow: /wp-login.php # block access to the admin section
Disallow: /readme.html # block access to the readme file
Disallow: /search/ # block access to internal search result pages
Disallow: *?s=* # block access to internal search result pages
Disallow: *?p=* # block access to pages for which permalinks fail
Disallow: *&p=* # block access to pages for which permalinks fail
Disallow: *&preview=* # block access to preview pages
Disallow: /tag/ # block access to tag pages
Disallow: /author/ # block access to author pages
Sitemap: https://www.example.com/sitemap_index.xmlWhile this code might be relevant for most WordPress sites, always perform adjustments and testing for the file to ensure it suits your specific situation and needs.
Common Actions with the robots.txt File
Here’s a table (desktop only) describing several common actions that can be taken with the robots.txt file. The table was taken directly from Google’s documentation.
Summary
In summary of the robots.txt guide, Reni wants to remind you that using the Disallow directive in this file is not the same as using the noindex meta tag.
It’s possible that the robots.txt file will prevent crawling of a specific address, but it won’t necessarily prevent its existence in the index and its appearance in search results.
You can use it to add specific rules and modify the way search engines interact with your site, but it doesn’t provide precise control over what content gets indexed and what doesn’t.
For the most part, website owners don’t need to deal with this file in a special way, and WordPress site owners likely don’t need to change the default virtual file.
However, if you encounter a specific issue with a certain bot or want to change how certain search engines access a plugin or a specific template you’re using, you might want to add dedicated rules to this file.

