הקובץ robots.txt מכיל הנחיות למנועי חיפוש לגבי האופן בו עליהם לסרוק את האתר שלכם. הנחיות אלו נקראות בלעז directives, וניתן להשתמש בהן כדי להנחות בוטים ולציין למנועי חיפוש מסוימים (או לכולם) להימנע מסריקת כתובות, קבצים, או חלקים מסוימים באתר שלכם.
בפוסט זה ניתן מבט מעמיק על קובץ זה, בין היתר בהקשר של אתרי וורדפרס. אני מאמין שתגלו מספר דברים שלא ידעתם על קובץ ייחודי זה.
אם אתם מעוניינים רק בשורה התחתונה – הנה הקוד לחסימת כל מנועי החיפוש מסריקת האתר שלכם:
User-agent: *
Disallow: /מה זה בעצם הקובץ robots.txt?
בוטים וסורקים הם חלק הכרחי מרשת האינטרנט. עם זאת, אין זה אומר שאתם רוצים שהם ייסרקו כל כתובת ותוכן באתר שלכם ללא הגבלה.
הרצון לשלוט בהתנהגות הבוטים הוביל ליצירת סטנדרט הנקרא Robots Exclusion Protocol. הקובץ robots.txt הוא היישום הפרקטי של סטנדרט זה – הוא מאפשר לכם להנחות בוטים של מנועי חיפוש כיצד לסרוק את האתר שלכם.
עבור מרבית בעלי האתרים, היתרונות של קובץ robots.txt מתחלקים לשתי קטגוריות:
- אופטימיזציה לתקציב הזחילה ולמשאבים שמנועי חיפוש מקדישים לאתר שלכם. זו נעשית על ידי הנחיה ובקשה להימנע מבזבוז משאבים בסריקת עמודים שאינכם רוצים באינדקס. פעולה זו מבטיחה כי מנועי חיפוש יתמקדו בסריקת העמודים החשובים ביותר באתר שלכם.
- אופטימיזציה לשרת עליו יושב האתר ומניעת עומסים בעקבות הסריקה. זו מתבצעת על ידי חסימת בוטים המבזבזים משאבים מיותרים בסריקת כתובות ותוכן שאינו רלוונטי.
robots.txt לא נועד לשליטה ספציפית על העמודים שיופיעו באינדקס
באמצעות robots.txt ניתן למנוע ממנועי חיפוש לגשת לחלקים מסוימים באתר שלכם, למנוע סריקה של תוכן משוכפל וכזה שאינו רלוונטי, ולספק אינפורמציה למנועי חיפוש על כיצד לסרוק את האתר שלכם בצורה יעילה יותר.
הקובץ מציין למנועי חיפוש אילו עמודים וקבצים ניתן לסרוק באתר שלכם. אך הוא אינו דרך מוחלטת לשליטה באילו עמודים יופיעו באינדקס של גוגל ואילו לא.
כדי למנוע מעמוד מסוים להופיע בתוצאות החיפוש, השתמשו בתגית noindex – ברמת הקוד בעמוד הספציפי או ברמת השרת (קובץ htaccess למשל).
למרות שרוב מקדמי אתרים שמעו לבטח את המונח robots.txt, אין זה אומר כי כי הם מבינים כיצד להשתמש בו נכון. לצערי ראיתי לא מעט הנחיות שגויות בנושא.
כיצד נראה קובץ robots.txt?
לאתר וורדפרס למשל, הקובץ robots.txt יכול להראות משהו בסגנון הבא:
User-agent: *
Disallow: /wp-admin/בואו נסביר את האנטומיה של קובץ robots.txt בהקשר של דוגמה זו:
- User-agent – מציין לאילו מנועי חיפוש ההנחיה המופיעה רלוונטית.
- כוכבית (*) – מציין כי ההנחיה רלוונטית עבור כל מנועי החיפוש ללא יוצא מן הכלל.
- Disallow – הנחיה זו המציינת איזה תוכן לא יהיה נגיש עבור ה user-agent שציינתם.
- /wp-admin/ – זהו הנתיב (path) שלא יהיה נגיש לאותו user-agent שציינתם.
ובמשפט אחד: הקובץ בדוגמה מעלה מציין לכל מנועי החיפוש לא לגשת לתיקייה /wp-admin/. בואו נתאר בהרחבה את הקומפוננטות השונות של קבצי robots.txt…
1. User-agent בקובץ robots.txt
על כל מנוע חיפוש להזדהות עם user-agent מסוים. הבוט של גוגל מזוהה כ Googlebot, בינג מזוהה כ BingBot, וסורקי AI כמו של OpenAI מזוהים כ GPTBot.
השורה user-agent מציינת את תחילתה של קבוצת הנחיות. כל ההנחיות הנמצאות בין ה user-agent הראשון שמופיע עד לזה שאחריו, מתייחסות ל user-agent הראשון.
2. ההנחיה Disallow בקובץ robots.txt
ניתן להנחות מנועי חיפוש לא לגשת לקבצים ולעמודים ספציפיים, או אף לחלקים שלמים באתר שלכם. ניתן לבצע זאת באמצעות ההנחיה Disallow.
על ההנחיה Disallow להופיע עם נתיב כלשהו אחריה, אותו נתיב שלא יהיה נגיש למנועי החיפוש. אם לא מוגדר נתיב, מנועי חיפוש יתעלמו מהנחייה זו.
User-agent: *
Disallow: /wp-admin/3. ההנחיה Allow בקובץ robots.txt
ההנחייה Allow משמשת לנטרול ספציפי של ההנחיה Disallow. שימוש בשתי אלו יחדיו מאפשר למנועי חיפוש גישה לקובץ או עמוד ספציפי שאחרת יהיה לא נגיש עבורם (לא נגיש ע״י ההנחיה Disallow כמובן).
על ההנחיה Allow גם כן להופיע עם נתיב כלשהו אחריה אליו אתם מעוניינים לספק גישה. אם לא מוגדר נתיב, ההנחיה לא רלוונטית ומנועי חיפוש יתעלמו ממנה.
User-agent: *
Allow: /media/terms-and-conditions.pdf
Disallow: /media/בדוגמה מעלה ההנחיה מציינת לכל מנועי החיפוש כי אין לגשת לספרייה /media/ למעט קובץ ה PDF המצויין בהנחיה Allow.
חשוב: כאשר משתמשים בהנחיות אלו יחדיו רצוי לא להשתמש ב wildcards מאחר וזה יכול להוביל להנחיות סותרות.
דוגמה להנחיות סותרות
User-agent: *
Allow: /directory
Disallow: *.htmlבסיטואציה זו מנועי חיפוש כנראה ויתבלבלו לגבי הכתובת http://domain.co.il/file.html למשל. אין זה ברור עבורם אם יש לסרוק קובץ זה או לא.
אם הנחיות מסויימות אינן ברורות מנועי חיפוש, או לפחות גוגל יתייחסו להנחיה הפחות מחמירה מבין השתיים, ובמקרה זה, הם יגשו לסרוק את הקובץ המדובר.
4. שורה נפרדת עבור כל הנחיה
על כל הנחיה להופיע בשורה נפרדת משל עצמה, אחרת מנועי חיפוש עלולים להתבלבל בהבנת ההנחיות בקובץ robots.txt, ולכן, המנעו מכתיבה בסגנון הבא:
User-agent: * Disallow: /directory-1/ Disallow: /directory-2/ Disallow: /directory-3/5. שימוש ב wildcards*
מעבר לשימוש של wildcards ב user-agent, ניתן להשתמש באלו גם עבור כתובות URL. למשל:
User-agent: *
Disallow: *?בדוגמה זו קיימת הנחיה למנועי החיפוש במציינת לא לגשת לשום כתובת URL בה קיים סימן שאלה (?).
6. שימוש בסיומת של כתובת URL ($)
ניתן להשתמש בסימן דולר ($) כדי לציין סיומת של כתובת URL לאחר הנתיב. לדוגמה:
User-agent: *
Disallow: *.php$ההנחיה בדוגמה זו היא לא לגשת ולסרוק אף כתובת URL בעלת הסיומת .php. לעומת זאת, לכתובות עם פרמטרים לאחר מכן תתאפשר גישה. לכתובת http://example.co.il/page.php?lang=he למשל תתאפשר גישה מאחר והיא אינה מסתיימת ב .php.
7. הצבעה למפת האתר ע״י קובץ robots.txt
למרות שקובץ robots.txt נועד להנחות מנועי חיפוש לאילו עמודים אין עליהם לגשת, הוא משמש גם כדי לציין לאלו היכן יושב קובץ ה XML Sitemap של האתר.
למרות שלבטח כבר הוספתם את אותה מפת אתר באמצעות Google Search Console או על ידי Bing Webmaster Tools, מומלץ לספק רפרנס לקובץ זה גם בקובץ robots.txt. ניתן כמובן לספק רפרנס למספר קבצי Sitemap שונים. הנה דוגמה:
User-agent: *
Disallow: /wp-admin/
Sitemap: http://example.co.il/sitemap1.xml
Sitemap: http://example.co.il/sitemap2.xmlההנחיה למנועי חיפוש בדוגמה זו היא לא לגשת לתיקייה /wp-admin/ ומעבר לכך מציינת להם כי קיימים שני קבצי Sitemap הנמצאים בכתובות שצויינו.
על הרפרנס לכתובת של קובץ ה Sitemap להיות אבסולוטי. מעבר לכך נציין כי הכתובת אינה חייבת להיות באותו שרת בו נמצא הקובץ robots.txt.
8. הוספת הערות בקובץ robots.txt
ניתן לכתוב הערות על ידי שימוש בסולמית (#). הערות אלו יכולות להופיע בתחילתה של שורה או לאחר ההנחיה באותה שורה בה היא מופיעה. מנועי חיפוש יתעלמו מכל מה שמופיע לאחר סולמית זו והערות אלו כמובן מיועדות לבני אדם בלבד. הנה דוגמה:
# Don't allow access to the /wp-admin/ directory for all robots.
User-agent: *
Disallow: /wp-admin/והנה דוגמה בה ההערה מופיעה באותה שורה של ההנחיה:
User-agent: * #Applies to all robots
Disallow: /wp-admin/ # Don't allow access to the /wp-admin/ directory.9. שימוש בהנחיה Crawl-delay בקובץ robots.txt
ההנחיה Crawl-delay אינה הנחיה רשמית. היא קיימת כדי למנוע עומס על השרת במהלך הסריקה עקב ריבוי בקשות.
אם הסריקה מעמיסה על השרת שלכם, Crawl-delay הוא רק פתרון זמני. בדרך כלל זה אומר שהאחסון שלכם חלש מדי, או שהאתר לא מוגדר כראוי.
הבוט של גוגל מתעלם לחלוטין מהנחיה זו. בעבר גוגל אפשרה לקבוע את תדירות הסריקה באמצעות גוגל סרץ׳ קונסול, אך אפשרות זו בוטלה.
בינג כן מתייחס להנחיה Crawl-delay. ההנחיה נראית כך:
User-agent: BingBot
Disallow: /private/
Crawl-delay: 10כיצד ליצור ולערוך את הקובץ robots.txt באתרי וורדפרס?
וורדפרס מייצרת אוטומטית קובץ robots.txt וירטואלי לאתר שלכם. גם אם אינכם מבצעים שום פעולה, כנראה שלאתר שלכם כבר קיים קובץ ברירת מחדל.
אתם יכולים לבדוק על ידי הוספת /robots.txt לאחר שם הדומיין שלכם. למשל, https://savvy.co.il/robots.txt יציג את קובץ ה robots.txt של סאבי בלוג.
אם הקובץ וירטואלי, לא תוכלו לערוך אותו. כדי לבצע שינויים עליכם ליצור קובץ פיזי בשרת. ניתן לעשות זאת במספר דרכים…
1. יצירת קובץ robots.txt באמצעות FTP
באפשרותכם כמובן ליצור ולערוך קובץ באמצעות תוכנת FTP כלשהי, אך בתור התחלה, השתמשו בכל עורך טקסט שבא לכם וצרו קובץ ריק בשם robots.txt.
לאחר מכן, התחברו לשרת שלכם ב FTP והעלו קובץ זה לתיקייה הראשית של האתר (root folder). כעת תוכלו לבצע מודיפיקציות נוספות לקובץ על ידי עריכתו בתוכנת ה FTP איתה אתם עובדים.
2. יצירה ועריכת הקובץ robots.txt באמצעות Yoast SEO
אם אתם משתמשים בתוסף Yoast SEO, תוכלו ליצור ולערוך את הקובץ robots.txt ישירות דרך ממשק התוסף. גשו ל SEO > כלים ולחצו על עריכת קבצים.
אם לא קיים קובץ robots.txt תופיע לכם האפשרות ליצור כזה. אם הקובץ קיים, תופיע אפשרות עריכה שלו יחד עם האפשרות לעריכת הקובץ .htaccess.
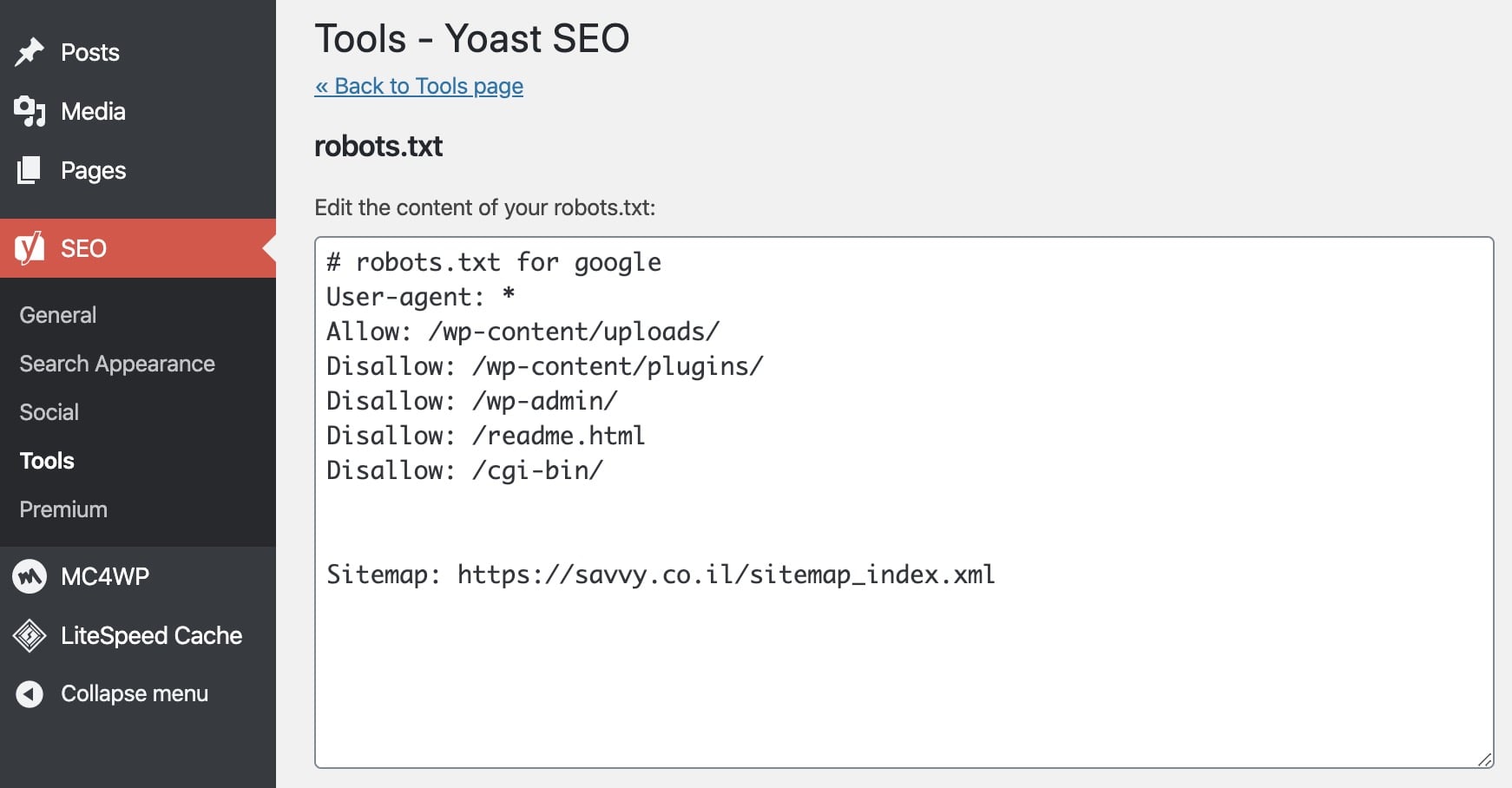
קובץ robots.txt אופייני לאתרי וורדפרס
הקוד הבא נועד ספציפית לאתרי וורדפרס, שימו לב כי הוא בגדר המלצה בלבד, ורלוונטי רק אם אתם:
- לא מעוניינים שממשק הניהול של וורדפרס (admin) ייסרק.
- אינכם רוצים שעמודי תוצאות החיפוש הפנימיים ייסרקו.
- אינכם מעוניינים כי עמודי התגיות (tags) ועמודי המחבר (author) ייסרקו .
- אתם משתמשים ב pretty permalinks כפי שרצוי שתעשו…
User-agent: *
Disallow: /wp-content/plugins/ #block access to the plugins folder
Disallow: /wp-login.php #block access to admin section
Disallow: /readme.html #block access to readme file
Disallow: /search/ #block access to internal search result pages
Disallow: *?s=* #block access to internal search result pages
Disallow: *?p=* #block access to pages for which permalinks fails
Disallow: *&p=* #block access to pages for which permalinks fails
Disallow: *&preview=* #block access to preview pages
Disallow: /tag/ #block access to tag pages
Disallow: /author/ #block access to author pages
Sitemap: https://www.example.com/sitemap_index.xmlלמרות שקוד זה רלוונטי עבור מרבית אתרי הוורדפרס, עליכם תמיד לבצע התאמות ובדיקות ולוודא שהוא מתאים לצרכים הספציפיים של האתר שלכם.
חסימת סורקי AI
בשנת 2025, חברות AI החלו לשלוח סורקים ייעודיים לגרד תוכן מהאינטרנט לצורך אימון מודלים. אם אתם רוצים למנוע שימוש בתוכן שלכם לאימון מודלי AI, הוסיפו את החוקים הבאים:
User-agent: GPTBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: CCBot
Disallow: /חוקים אלו חוסמים את סורקי האימון העיקריים: GPTBot של OpenAI, Google-Extended (לאימון Gemini), ClaudeBot של Anthropic, ו-CCBot של Common Crawl.
חסימת
Google-Extendedלא משפיעה על הדירוג שלכם בתוצאות החיפוש של גוגל. היא רק מונעת שימוש בתוכן שלכם לאימון מודלי ה-AI של גוגל.
שימו לב שסורקי AI מבוססי ציטוטים כמו PerplexityBot ו-ChatGPT-User מספקים קישורים חזרה ותנועה לאתר. בדרך כלל לא מומלץ לחסום אותם.
למדריך מעמיק בנושא, קראו את הפוסט שלנו על חסימת סורקי AI באמצעות robots.txt.
ביצוע בדיקות לקובץ robots.txt
ניתן לבדוק את קובץ robots.txt דרך Google search Console בקישור זה כדי לוודא שהוא מוגדר כראוי. באפשרותכם להכניס כתובת URL כלשהי באתר שלכם, ואם היא אינה חסומה לגישה יופיע לכם בירוק המילה ״מורשית״ בצבע ירוק.
לעומת זאת, אם כתובת מסויימת חסומה על ידי robots.txt תופיע בפניכם באדום המילה ״חסומה״.
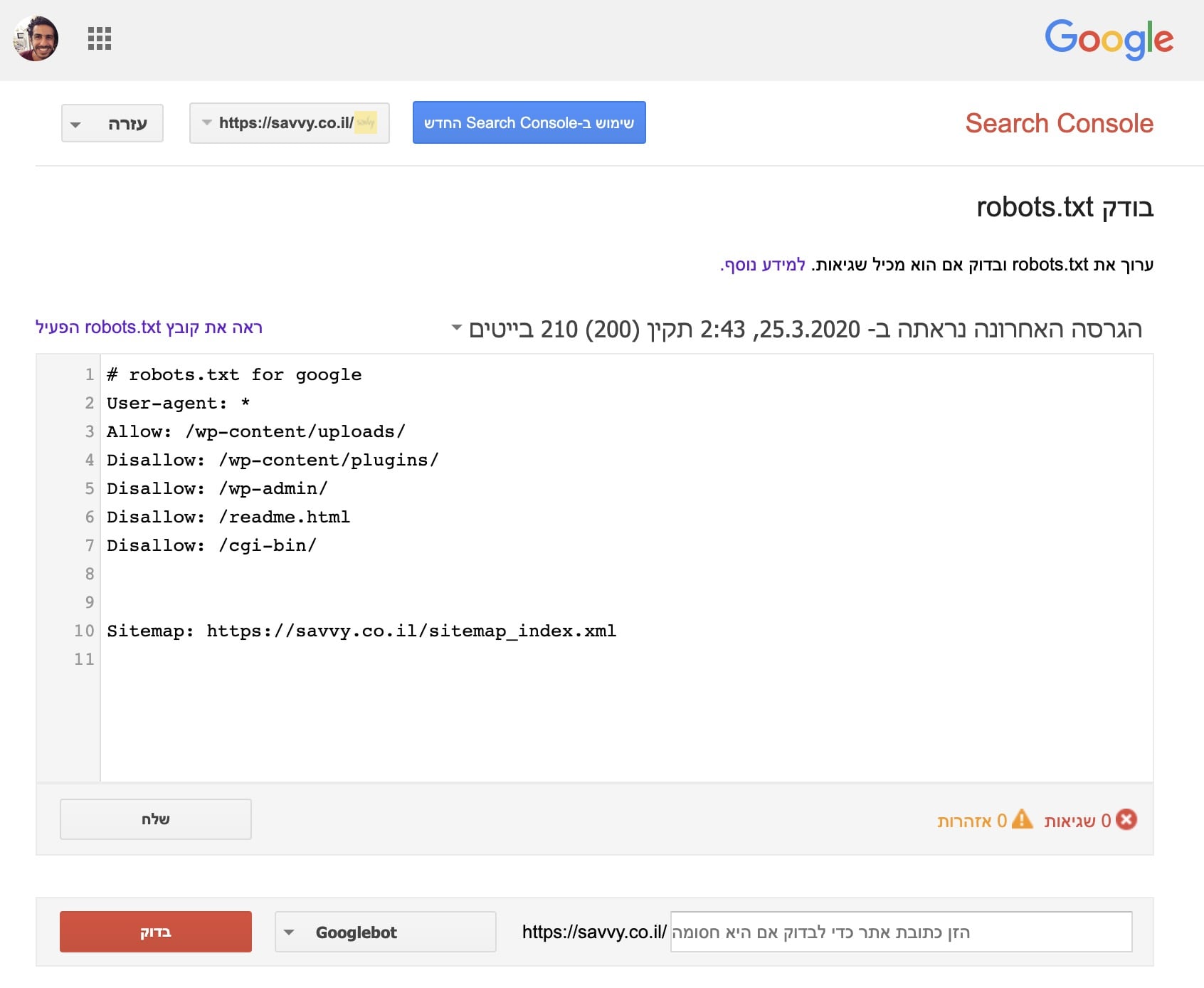
מגבלות הקובץ robots.txt
עליכם לדעת את המגבלות הקיימות לפני שיוצרים או עורכים את הקובץ robots.txt. אז הנה מספר מגבלות ונקודות שחשוב לדעת:
- לא כל מנועי החיפוש מצייתים להנחיות המופיעות בקובץ robots.txt. לכן, אם אתם מעוניינים לחסום גישה לכתובת URL או קבצים כלשהם בצורה מוחלטת, נכון יהיה אולי להשתמש בסיסמה.
- סורקים שונים מפרשים את ההנחיות בצורה שונה כפי שראינו במאמר. עליכם להשתמש בסינטקס הרלוונטי והמתאים עבור הסורקים השונים.
- עמוד החסום ב robots.txt עדיין יכול להופיע באינדקס אם קיים קישור לזה מאתרים אחרים ברשת.
- קובץ robots.txt בדרך כלל נשמר בזכרון (cache) לכ – 24 שעות.
- גוגל תומכת בקובץ עד ל 512KB (קילובייטס) וייתכן שאינה תתייחס להנחיות מעבר לכך.
מספר שאלות ונקודות חשובות בהקשר של robots.txt
הנה מספר שאלות נפוצות בהן אני נתקל לא פעם ברשת וברשתות החברתיות השונות:
1. האם אני צריך קובץ robots.txt? כן. עליכם לדאוג כי קובץ זה קיים מכיוון שהוא משחק תפקיד חשוב מנקודת המבט של קידום אתרים ו SEO. מבחינה זו, הקובץ מספק מידע למנועי חיפוש על הדרך הטובה ביותר לסרוק את האתר שלכם.
2. האם האתר שלי יסרק ללא קובץ robots.txt? כן. אם מנועי חיפוש לא מוצאים קובץ זה בתיקייה הראשית של האתר הם יניחו כי שלא קיימות הנחיות והגבלות כלל ויסרקו את כל האתר.
3. האם זה חוקי לסרוק אתר ולהתעלם מההנחיות? מנקודת מבט טכנית, כן. הקובץ כפי שציינו מהווה הנחיה בלבד ואינכם יכולים לבוא לאף אחד שסורק את האתר שלכם בטענות (לפחות לא כאלו הקשורות להנחיות המופיעות ב robots.txt).
4. יש להיזהר כשמבצעים שינויים לקובץ robots.txt. לקובץ פונטנציאל לגרום לחלקים מסוימים או אף לכל האתר שלכם להיות בלתי נגיש למנועי חיפוש.
5. מנועי חיפוש שונים מתייחסים להנחיות המופיעות בו בצורה שונה. כברירת מחדל, ההוראה הראשונה לה נמצאה התאמה מנצחת (first matching directive). אך מבחינת גוגל ו Bing ספציפית, הייחודיות מנצחת (specificity).
6. המנעו משימוש בהוראה crawl-delay ככל שניתן.
7. הזהרו מ UTF-8 DOM. אותו BOM הוא בעצם אות אינה נראית כלשהי הנוספת לעיתים על ידי עורכי טקסט כאלו ואחרים. אם אותו character בלתי נראה קיים בקובץ ייתכן ומנועי חיפוש לא יפרשו את ההנחיות הנמצאות בו כראוי.
פעולות נפוצות עם הקובץ robots.txt
הנה טבלה (בדסקטופ בלבד) המתארת מספר פעולות נפוצות שניתן לבצע עם הקובץ robots.txt. הטבלה נלקחה היישר מהדוקומנטציה של גוגל.
שליטה בגישה של בינה מלאכותית (AI) עם llms.txt
בעוד ש-robots.txt חוסם סורקי AI ברמת הגישה, תקן חדש יותר לוקח גישה שונה. הקובץ llms.txt מאפשר לכם להגדיר כיצד מודלי AI צריכים להציג ולהשתמש בתוכן שלכם.
חשבו על זה כמשלים ל-robots.txt – במקום לחסום AI לחלוטין, אתם יכולים להנחות כיצד התוכן שלכם מופיע בתשובות שנוצרות על ידי AI.
למדו כיצד להגדיר ולהשתמש בקובץ במדריך על llms.txt למנועי בינה מלאכותית.
שאלות נפוצות
הנה השאלות הנפוצות ביותר בנושא robots.txt והדרך בה הוא פועל.
noindex בעמוד עצמו.https://example.com/robots.txt. הוא חל רק על הפרוטוקול, ההוסט והפורט הספציפיים בהם הוא נמצא.User-agent: GPTBot ואחריו Disallow: / כדי לחסום את הסורק של OpenAI. אותה גישה עובדת עבור ClaudeBot, Google-Extended, CCBot וסורקי AI נוספים. חסימתם לא משפיעה על הדירוג שלכם בגוגל.לסיכום
הנקודה החשובה ביותר: שימוש בהנחיית Disallow בקובץ robots.txt אינו כשימוש בתגית noindex. חסימת כתובת מסריקה לא בהכרח תמנע את הופעתה באינדקס או בתוצאות החיפוש.
ניתן להשתמש ב-robots.txt כדי לעצב את הדרך בה מנועי חיפוש מתקשרים עם האתר שלכם. אבל הוא לא מספק שליטה מדויקת על מה שמאונדקס ומה לא.
לרוב בעלי אתרי הוורדפרס אין צורך לגעת בקובץ הוירטואלי הדיפולטיבי. אבל אם אתם מתמודדים עם בוט בעייתי, רוצים לחסום סורקי AI, או לשפר את הגישה של מנועי חיפוש לחלקים ספציפיים באתר – הוספת חוקים מותאמים שווה את המאמץ.
אני ממליץ לסקור את קובץ ה-robots.txt שלכם לפחות פעם בשנה, במיוחד כשעולם סורקי ה-AI ממשיך להשתנות.


כל התיקיות של הניהול לא אמורות להיות חסומות אוטומטית? הרובוטים גם לא חייבים לפעול לפי מה שכתוב בקובץ? זה לא בסדר
תודה על המאמר, מחכים וכתוב יפה
תודה שביקרת ענת 🙂